
B-Tree는 데이터베이스 인덱스를 공부하면서 처음 알게된 자료구조입니다.
B트리는 어떤 구조로 데이터를 조회, 삽입, 삭제할 수 있는지 알아보곘습니다.
너무 재밌겠죵?

B-Tree란
이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리 구조
특징
M차 B-Tree : 최대 M개의 자식을 가질 수 있는 B-Tree
- M : 각 노드의 최대 자녀 수
- M-1 : 각 노드의 최대 데이터(Key) 수
- ⌈M/2⌉(올림) : 각 노드의 최소 자녀의 수
- ⌈M/2⌉-1 : 각 노드의 최소 데이터(Key)의 수
- Internal노드의 key가 x개라면 자녀 노드 수는 항상 x+1개이다
*즉, 모든 노드는 1개이상의 데이터(key)를 가지므로 자녀는 항상 2개 이상이다.
*internal노드는 리프노드를 제외한 모든 노드 ⇒ 루프노드, 중간 노드 - 노드의 Key들은 항상 정렬된 상태를 유지한다.
그럼 이진트리와 B-Tree의 차이점이 궁금하지 않나요?
네 왕궁금해요

이진트리 vs B-Tree
| 항목 | 이진 탐색 트리(BST) | B-Tree |
| 노드 당 자식 수 | 최대 2개 (왼쪽: 작음 / 오른쪽: 큼) | 여러 개 (최대 M개의 자식, M은 차수) |
| 노드 당 키 수 | 최대 1개 | 여러 개 (최대 M-1개 키) |
| 트리 높이 | O(N) (편향되면 최악) / AVL, Red-Black Tree 쓰면 O(log N) | O(log N), 항상 균형 유지 |
| 디스크 I/O | 비효율적 (트리 노드가 작아서 I/O 많이 발생) | 매우 효율적 (한 노드가 여러 키, 자식 포함 — 디스크 접근 최소화) |
| 탐색 시간 복잡도 | O(log N) (균형 잡힌 경우) | O(log N) (항상 보장) |
| 삽입 / 삭제 | O(log N), 노드 하나만 재배열 | O(log N), 노드 분할/병합 발생 가능 |
| 범위 조회 (Range Query) | 느림 (In-order traversal 필요) | 빠름 (리프 노드가 연결 리스트처럼 연결되어 있음) |
| 사용 사례 | 메모리 내 데이터 구조 (예: 트리맵, 집합) | 디스크 기반 인덱스, 데이터베이스, 파일 시스템 등 |
이진 트리는 편향될 경우, O(N)으로 최악의 시간복잡도를 가진다.
반면에 B-Tree는 언제어디서나 당당하게 ~ O(logN)의 시간복잡도를 가진다!
B-Tree가 O(logN)의 시간복잡도를 가지는 이유 : 밸런스 트리
밸런스트리(Balanced Tree)
트리의 노드가 한 방향으로 쏠리지 않도록, 노드 삽입 및 삭제 시 특정 규칙에 맞게 재정렬되어 왼쪽과 오른쪽 자식 양쪽 수의 밸런스를 유지하는 트리
=> 항상 양쪽 자식의 밸런스를 유지하므로, 무조건 O(logN)의 시간 복잡도를 가지게 된다.
다만 재정렬되는 작업으로 인해 노드 삽입 및 삭제 시 일반적인 트리보다 성능이 떨어지게 된다. 그러므로 밸런스 트리는 삽입/삭제의 성능을 희생하고 “탐색에 대한 성능을 높였다”고 볼 수 있다.
- 예) RedBlock-Tree, B-Tree
이처럼 B-Tree는 "균형 트리(Balanced Tree)"이기 때문에 항상 O(logN)의 시간복잡도를 가질 수 있다.

B-Tree 조회 과정
- B-Tree는 항상 정렬되어 있다.
- 왼쪽 자식 노드는 항상 부모보다 작다
- 오른쪽 자식 노드는 항상 부모보다 크다
# 9 조회

1. 9는 10보다 작으므로 10의 왼쪽 자식을 탐색한다.
2. 9는 7보다 크므로 7의 오른쪽 자식을 탐색한다.
3. 9를 찾는다.
위의 과정으로 탐색의 시간복잡도는 트리의 높이 == O(logN)이다
B-Tree 삽입 과정
- 삽입은 항상 Leaf노드에서 삽입
- 노드가 넘치면 가운데 key(중간값 키)를 기준으로 좌우 key들을 분할 하고 가운데 key는 부모로 승진*노드 넘침 : M차 B트리는 최대 M-1개의 key를 가질 수 있는데 데이터를 삽입하는 과정에서 이를 위반한 것
< 삽입 과정 >
1. 트리가 비어있다면, 루트노드를 할당하고 새로운 key를 삽입
2. 트리가 비어있지 않다면, 데이터를 넣을 적절한 리프노드 탐색(O(logN)
3. 리프노드에 데이터를 넣고 리프노드가 적절한 상태에 있다면 종료
4. 리프노드가 부적절한 상태(ex. 노드넘침)에 있다면 분리 및 재정비
<< 3차 B-Tree >>

# 12 삽입

10 < 12 < 20 ➡️ 12 < 16 ➡️ 11 < 12
리프노드에 12를 삽입했을 때, 최대로 가질 수 있는 key의 수를 만족함으로 완료
# 13 삽입
①

10 < 13 < 20 ➡️ 13 < 16 ➡️ 11 < 13
리프노드에 13를 삽입했을 때, 최대로 가질 수 있는 key의 수(2)를 초과하므로
→ 리프노드의 중간값(12)을 기준으로 양쪽으로 분리하고
→ 중간값(12)은 부모로 승진시킴
②

다시, internal 노드도 최대로 가질 수 있는 key의 수(2)를 초과하므로
→ internal 노드의 중간값(16)을 기준으로 양쪽으로 분리하고
→ 중간값(16)은 부모로 승진시킴
③
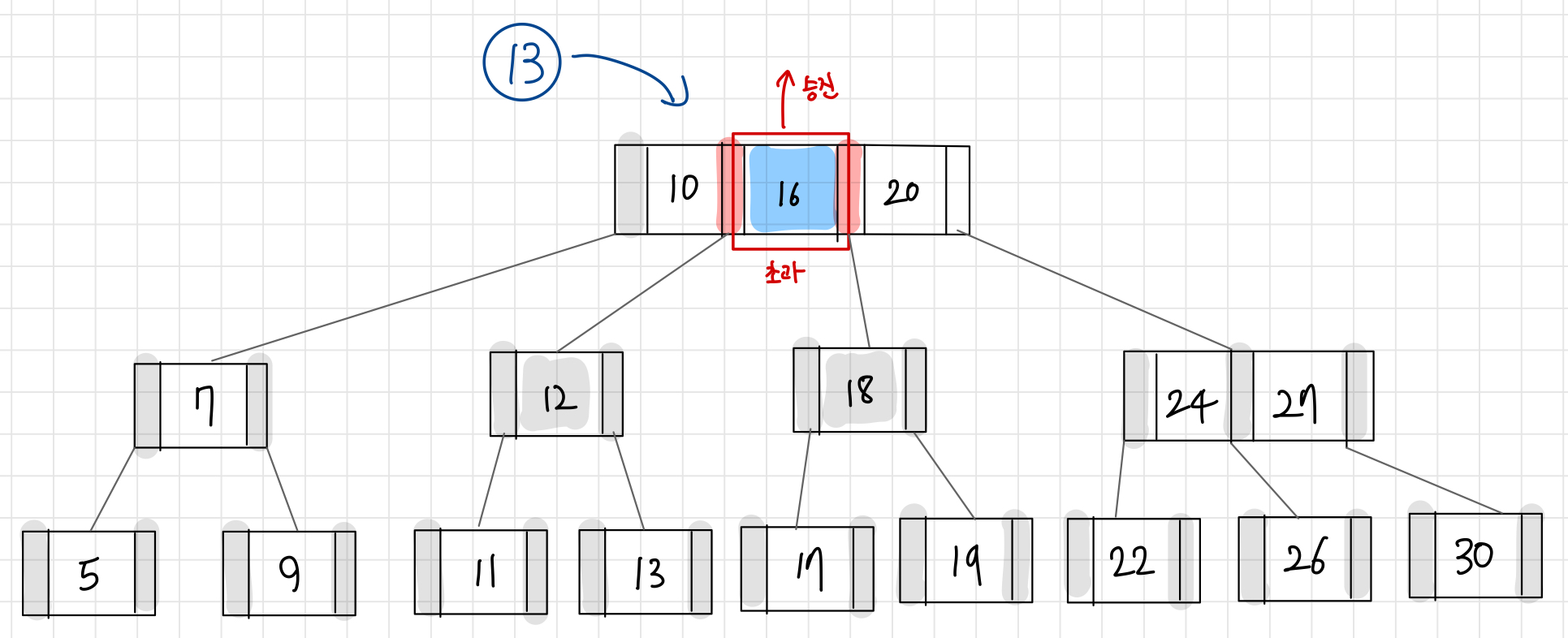
다시, 루트노드(internal)도 최대로 가질 수 있는 key의 수(2)를 초과하므로
→ 루트노드의 중간값(16)을 기준으로 양쪽으로 분리하고
→ 중간값(16)은 부모로 승진시킴
④ 최종 결과

이제 슬렁슬렁 감이 오시나요???
ㅎㅎ 아직 삭제가 남았습니다~
(이건 더 복잡함)

B-Tree 삭제 과정
- 삭제도 항상 Leaf노드에서 발생
- 삭제 후, 최소 Key 수보다 적어졌다면 재조정
< 재조정 과정 >
1. Key수가 여유있는 형제의 지원을 받음(둘다면, 왼쪽 만만한 동생부터)
2. 1번이 불가능하면, 부모의 지원을 받고 형제와 합침.
3. 2번 후, 부모에 문제가 있다면 해당 부분에서 다시 재조정

# 17 삭제
① 재조정 필요 X

17을 삭제해도, 노드의 최소 key의 개수(1)를 만족하므로 종료
# 16 삭제
② 재조정 필요 O : 형제 지원

16을 삭제하면, 노드의 최소 key의 개수(1)보다 작아지므로(0이 됨) 재조정이 필요하다
✔️ 형제 중에서 여유있는 형제가 있으므로 형제에게 지원받기
→ 왼쪽(동생) or 오른쪽(형) 중에 더 여유있는 형제에게 지원받기
단, 형제의 것을 바로 가져오면 12가 15보다 작은데 큰 값을 가리키는 노드로 가기때문에 불가능
→ 정렬된 순서가 깨지게됨
따라서 형제를 부모로 승진하고, 나와 형제 사이의 부모 노드 key를 가져온다. (12 ↔ 15)
→ 형제에게 지원받는 재조정 시, 부모를 거쳐서 받는다

# 15 삭제
③ 재조정 필요 O : 부모 지원

15를 삭제하면, 노드의 최소 key의 개수(1)보다 작아지므로(0이 됨) 재조정이 필요하다.
✔️ 여유있는 형제가 없으므로, 부모에게 지원받고 + 형제외 합치기
1. 동생(왼쪽 노드)이 있으면 동생과 나 사이의 Key를 부모로부터 받음
→ 나의 key(15)삭제
→ 동생의 key와 부모에게서 받은 key 합치기
2. 동생이 없으면 형과 나 사이의 Key를 부모로부터 받음
→ 나의 key(15) 삭제
→ 형의 Key와 부모에게서 받은 key 합치기

# 24 삭제
④ internal 노드 삭제 : Leaf 노드 key와 위치 바꾼 후 삭제

24는 리프노드 key가 아니므로 리프노드에 있는 데이터(key)와 변경한 후 삭제해야 한다
✔️ 어떤 Leaf노드와 바꿀것 인가?
⇒ 삭제할 선임자 or 후임자와 위치를 바꿔줌
- 선임자(predecessor) : 나보다 작은 데이터들 중 가장 큰 값
- 후임자(successor) : 나보다 큰 데이터들 중 가장 작은 값
즉, 나보다 작은 데이터들 중 가장 큰 값인 22와 변경한 후 삭제한다.

또한, 변경 후 24를 삭제하게 되면 노드의 최소 key의 개수(1)보다 작아지므로(0이 됨) 재조정이 필요하다.
→ 여유있는 형제가 없으므로 부모지원(22) + 형제(26)와 합침

Q. B-Tree 삽입 or 삭제시 노드에서의 key 정렬과정에도 O(logN)을 유지하는 이유
노드 내부의 작업은 대부분 “고정된 크기(상수)”에서 이루어지기 때문
B-Tree의 한 노드의 크기는 디스크의 블록 크기에 맞춘다.(보통 4KB 블록당 키가 200개)
노드 내 키 개수는 N(전체 키 수)와 무관하게 항상 상수로 제한됨
⇒ 왜냐하면 한 노드안의 키들은 항상 정렬되어 있기 때문에 새로운 키를 삽입하면 적절한 위치를 선택하고(O(logB)) + 선택한 위치에 새로운 키를 삽입해서 뒤에 있는 키들을 밀어야(O(B)) 하므로 총 O(logB + B) ⇒ O(B)가 된다.
따라서 노드 내부에서 정렬된 위치를 찾는 것은 O(logB), 삽입 or 삭제로 shift하는 것은 O(B)이고, 이 값은 "상수"이므로
전체 시간복잡도는 O(logN)
Q. DB 인덱스에 B-Tree계열을 사용한 이유
- 항상 정렬된 특정 값보다 크고 작은 부등호 연산에 문제가 없다.
- 참조 포인터가 적어 방대한 데이터 양에도 빠른 메모리 접근이 가능하다
- 데이터 탐색뿐 아니라 저장, 수정, 삭제에도 항상 O(logN)의 시간복잡도를 가진다
굉장해 엄청나 오랜만에
굉장히 엄청해 개념을 정리해보았는데요~
지쳤나요? 네니오.

참고
- https://helloinyong.tistory.com/296
- https://velog.io/@onejaejae/B-Tree가-왜-DB-인덱스index로-사용되는지#인덱스로-성능-비교-전-몇-가지-가정
- https://velog.io/@agugu95/이진-트리의-균형-RED-BALCKAVL#red-black-vs-avl
감사합니다 탱쿠
'CS' 카테고리의 다른 글
| [Java] String equals() 비교 (0) | 2025.02.19 |
|---|---|
| [Java] HashMap, LinkedHashMap, TreeMap (0) | 2025.02.17 |
| DAO, DTO, VO, Entity (0) | 2025.01.20 |
| [Java] 자바 데이터 타입 & 변수 종류 (0) | 2024.07.15 |
| [Java] JVM 메모리 구조 & Java의 Call by Value (0) | 2024.07.15 |